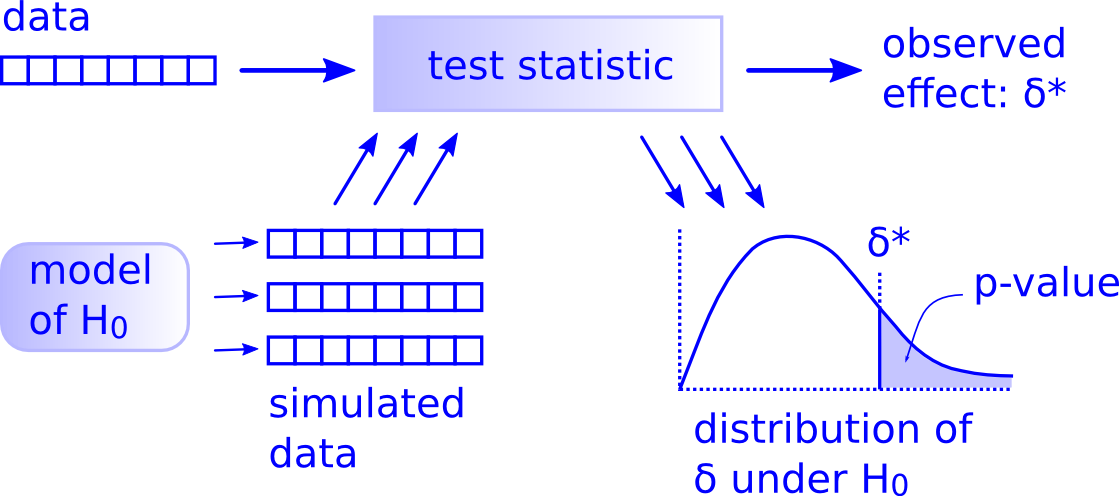
"That’s it. All hypothesis tests fit into this framework. The reason there are so many names for so many supposedly different tests is that each name corresponds to + A test statistic, + A model of a null hypothesis, and usually, + An analytic method that computes or approximates the p-value.
These analytic methods were necessary when computation was slow and expensive, but as computation gets cheaper and faster, they are less appealing because:
+ They are inflexible: If you use a standard test you are committed to using a particular test statistic and a particular model of the null hypothesis. You might have to use a test statistic that is not appropriate for your problem domain, only because it lends itself to analysis. And if the problem you are trying to solve doesn’t fit an off-the-shelf model, you are out of luck.
+ They are opaque: The null hypothesis is a model, which means it is a simplification of the world. For any real-world scenario, there are many possible models, based on different assumptions. In most standard tests, these assumptions are implicit, and it is not easy to know whether is a model is appropriate for a particular scenario."
\(e^{\lambda}=\sum_{n=0}^{\infty} \frac{\lambda^n}{n!} = 1/1+\lambda/1+\lambda^2/2..\)
“We see the first term is always 1 You can use the fact that the first term in this power expansion is one to reason about why something raised to the zero power is one and not zero. and then after that we get a series of terms that change in size following a nice pattern. To get the ith step we simply take the (j−1)th step and multiply it by λ and divide it by j (sj+1=sjλ/j.) It’s quite beautiful in its simplicity. By carrying this process out an infinite number of times our sum will converge to the true value of eλ, and rather rapidly at that.”
“The U.S. moved to chip & signature in October of 2016. This has forced attackers to find different, creative ways to get your credit card info. Yes, there were scads of breaches this year, but a good chunk of digital crime is plain ‘ol theft. Web sites make great targets. Public Wi-Fi makes a great target. You need to protect yourself since no store, org, bank, politician or authority really cares that your identity was stolen. If they did, we wouldn’t be in the breach mess we’re in now. Attackers know you’re in deep “breach fatigue” and figure you’re all in a “Meh. Nothing matters” mood. Don’t be pwnd! A wrong move could put you in identity theft limbo for years."
“It’s hard to comprehend how huge Amazon’s holdings are now. But consider: The biggest casino in Las Vegas (that’d be the Wynn and Encore complex) is 186,000 square feet, which is less than .06 percent of the size of Amazon’s real-estate holdings. The biggest Walmart Supercenter anyone’s ever seen is roughly 260,000 square feet; Amazon has added facilities equivalent to 590 of that store in the past three years.”
“When it came to directly addressing our question of interest regarding price spreading, I opted to group all non-Auckland regions together and compare average prices there with those in Auckland. There are better ways of modelling this that make full use of the granular data available (mostly involving mixed effects models, and more complex ways of representing the trend over time than linearly; and they would certainly take into account weighting from the spread in population over regions) but they come with big costs in complexity that I don’t have time for right now. Plus, the difference-of-averages method struck me as the easiest way to interpret and communicate, not to mention think about, the question of whether prices were converging back towards eachother after the initial shock of the addition of the tax.”

“One surprise for me is the complete absence of predictive power of merchandise goods exports for growth in GDP…These confidence intervals come from what I believe to be a pretty robust frequentist modelling approach that combines multiple imputation, bootstrap and elastic net regularization. I have in the back of my head the idea of a follow-up project that uses Bayesian methods to provide actual forecasts of the coming GDP, but I may not get around to it (or if I do, it will probably be for Victorian or Australian data seeing as I’ll be living there from October and more motivated for forecasts in that space).”

“GAM or MLR have assumptions in a model that errors (residuals) are identically and independently distributed (i.i.d.). In the case of the time series regression, it is very strong assumption, which is here, logically, not fulfilled. Present time series values are highly correlated with past values, so errors of the model will be correlated too. This phenomenon is called an autocorrelation. This implies that estimated regression coefficients and residuals of a model might be negatively biased, which also implies that previously computed p-values of statistical tests or confidence intervals are wrong.”
- Use tools you don’t have to ask permission to install (i.e. open source).
- Dependence on tools that are closed license and un-scriptable will limit the scope of problems you can solve. (i.e. Excel) Use them, but build your core skills on more portable & scalable technologies.
- Be sure you know the handful of things that you can do better than most anyone else. Add something to that list every year. Make sure you can explain these things to non techies.